The dataset and its documentation are hosted on the official GitHub repository. Please visit the repository for download links, data format, and usage instructions.

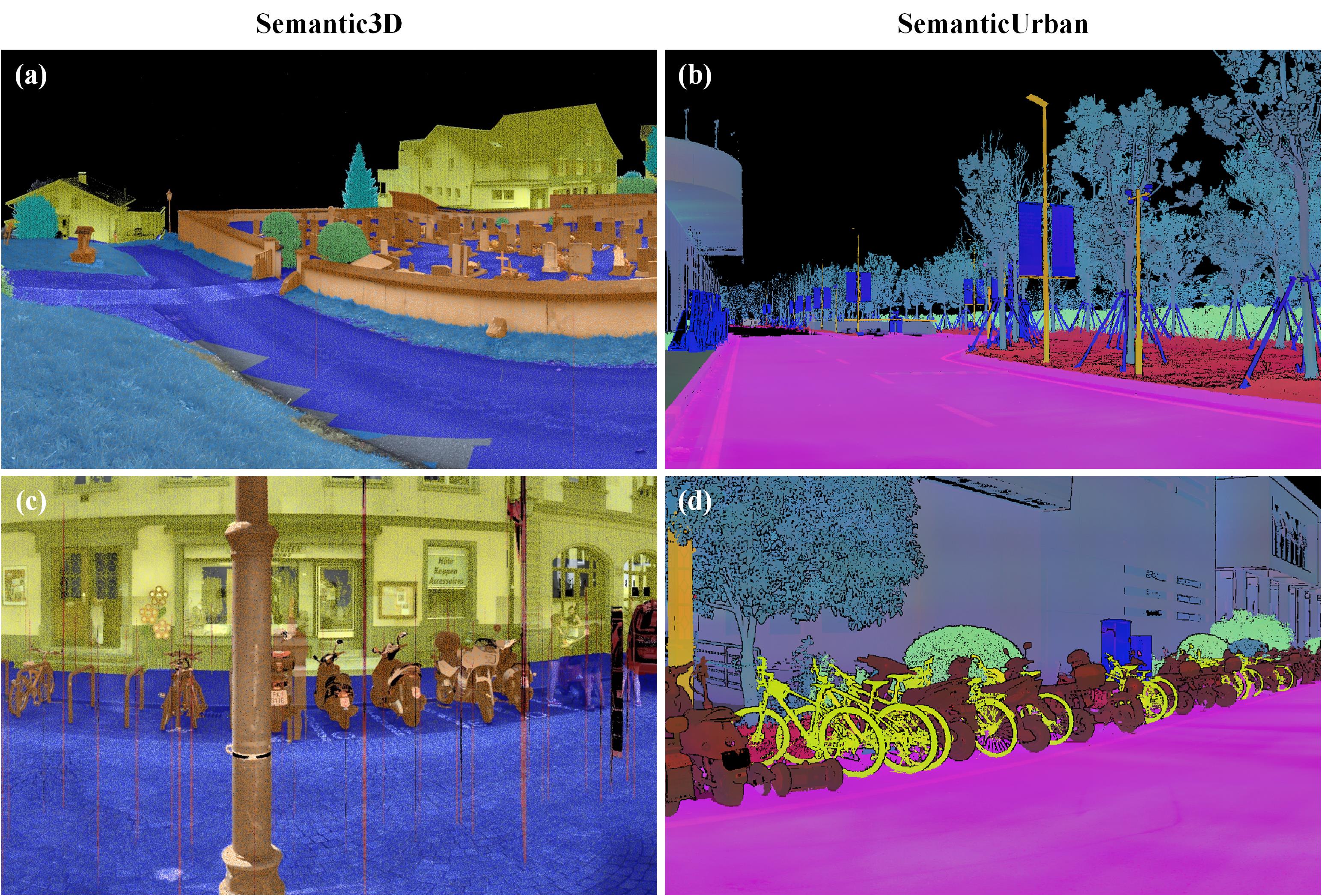
Point clouds are essential data representations of three-dimensional surfaces of real-world scenes and objects. With the recent developments in urban scene understanding, there is a substantial demand for semantic point cloud datasets that represent urban scenes with high semantic accuracy and fine semantic details. However, existing benchmark datasets of this kind are very limited, and their semantic information is either not accurate enough or lacks detailed semantic classification. In this paper, we present SemanticUrban, a large-scale high-resolution point cloud dataset acquired from 150 urban scenes using terrestrial laser scanning. SemanticUrban features super-high-resolution point clouds and highly accurate semantic categorizations, classifying each data point into one of 23 defined classes. We conduct extensive evaluations on SemanticUrban using representative deep learning methods, followed by a detailed discussion of our findings. Additionally, we highlight main challenges associated with the SemanticUrban dataset, motivating future research to develop new approaches for tackling these issues.
SemanticUrban is a large-scale, high-resolution point cloud dataset acquired from 150 urban scenes using terrestrial laser scanning (TLS), collected from four first-tier cities in China. It contains approximately 4 billion points, each manually annotated into one of 23 semantic classes. The dataset provides super-high-resolution geometry, accurate object boundaries, and intensity together with RGB color information, supporting urban scene understanding tasks such as semantic segmentation, mapping, navigation, and urban planning.
| Scenes | 150 |
| Number of points | ~4 billion (all labelled) |
| Semantic classes | 23 |
| Sensor | Leica RTC 360 (TLS with HDR imaging) |
| Field of view | 360° horizontal / 300° vertical |
| Per-point information | 3D coordinates, intensity, RGB |
| Official split | 105 train / 15 val / 30 test |
23 semantic classes
Distortion, Road, Other man-made terrain, Building, Wall, Fence, Pole, Stairs, Traffic sign, Shrub, Tree, Grass, Soil, Person, Car, Truck, Other vehicle, Bridge, Motorcycle, Bicycle, Clutter and rubbish, Flowerbed, Reflections.
Unannotated points (label 0) are ignored during training and evaluation.
The dataset and its documentation are hosted on the official GitHub repository. Please visit the repository for download links, data format, and usage instructions.
The released package is the preprocessed benchmark version (voxel size 0.05 m). To request the raw data, please email the corresponding author at Lei.Fan@xjtlu.edu.cn.






@article{FANG2026132949,
title = {Towards Accurate Urban Scene Understanding using Point Clouds: The SemanticUrban Dataset},
author = {Yuan Fang and Qinfeng Zhu and Yuanzhi Cai and Lei Fan},
journal = {Expert Systems with Applications},
pages = {132949},
year = {2026},
issn = {0957-4174},
doi = {https://doi.org/10.1016/j.eswa.2026.132949}
}The dataset and its documentation are available at the GitHub repository: https://github.com/YuanFangFF/SemanticUrban.